
A Separation of Errors
Service monitoring, part art, part science. What I attempt to do in this series of posts on metrics is to lay down some basic principles that I have found to be helpful without being too prescriptive.

Monitoring a service for errors has a specific set of concerns that run somewhat orthogonally to how programming languages expose errors. To a programming language, an error is an error and as a developer, we are left to deal with it once it happens. Service errors are also orthogonally separate from protocol/transport level errors. A network transport protocol is concerned with the reliability of communication of data and is unconcerned with any errors unrelated to transport. However, as a service owner, one error is not the same as another error. Solving for a network partition error might require a completely different approach than solving for a missing API key. Furthermore, some errors are a normal part of programming against a physical world with physical limits and are part of the application processing flow itself. Problems arise, however, when all errors are just treated as errors and there is not clear heuristic for how to tell them apart.
It can be helpful to think of an application as a black box that has gauges on the outside that tell you what’s going on inside. We as developers are responsible for wiring those gauges to the things that we want to know about. And when the gauges start spiking, we would prefer if the gauge could actually tell us something about where things are going wrong, not just that something is going wrong. And if your black box is dependent on another black box, you want to know if it is your black box that is causing the error or if the problem is in another black box at the other end of a wire.
I generally believe that effective service operations involve being able (1) tell at a glance on a service dashboard if it is operating within expected parameters, and (2) have faith that if a new health condition affects my service, I can see it in the dashboard and classify it one of three domains: Server fault, client fault, or processing error. I like these domains because they attempt to completely separate the space into separate responsibility domains.
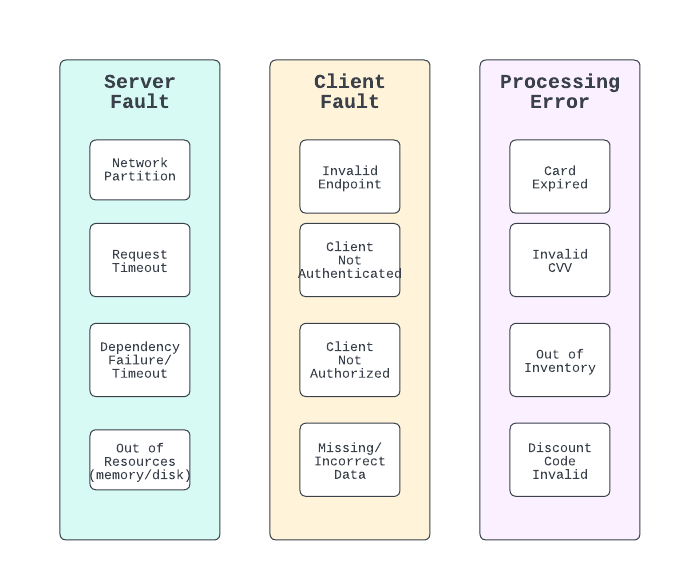
A Server Fault has the following characteristics: (1) It is 100% the responsibility of the service owner to fix, (2) counts against the service’s availability metric, (3) while not possible to drive to zero, driving to zero should always be a goal and (4) is always a reflection of the sum of the system design and engineering that have been applied to the service and the availability of its upstream dependencies. These errors count because they reduce the availability of the overall business and can have a direct impact on revenue for better or for worse in a big way.
In the worst possible case, if the availability of a service drops significantly, it has huge impact on all customers of our service, causing a direct drop in revenue. In the best possible, case a service with high availability can easily beat out any other competitor in an A/B test even with inferior CX, simply by being more available.
Driving to a high service availability posture can produce a sense of pride in the owning team and every order of magnitude increase in availability (adding a '9) requires a whole new set of engineering skills and advantages in availability can lead to overwhelmingly crushing defeats when comparing like competitors. When a server fault alarm goes off, the service owner is 100% responsible for fixing it.
A Client Fault has the following characteristics: (1) Is is 100% the responsibility of the client to fix (putting aside service-vended client scenarios). (2) Almost always indicates a bug or misconfiguration in the client code or lack of data validation. When a client fault alarm goes off, the the owner of the client is 100% responsible for fixing it.
A Processing Error has the following characteristics: (1) unlike server and client faults, processing errors are intentionally produced by the system and are usually expected and explainable based on some physical resource state or constraint, and (2) there will always be some sort of rate of these errors, which may or may not be predictable. Processing errors happen because as a normal fact of life, the application has to honor all of the rules of the system which usually map to resources in the physical world. Products cannot be sold that are not in inventory. Credit cards cannot be honored if they are expired or over limit. Addresses cannot be shipped to if they do not exist. Monitoring these errors is important from a business perspective to understand “how” the system is operating. Monitoring generally requires some understanding of what “normal” error rate is and may require investigation only when deviance from normal is observed.
Service Endpoint Error Handling
In order for a service endpoint to reliably emit observable metrics, here are some opinionated heuristics for service response behavior and metrics behavior related to errors:
The handler for a service endpoint should emit a reliable, observable metric stream that classifies errors into (a) Service Faults, (b) Client Faults, and (c) Processing Errors.
Error metrics are emitted with a separate (more useful) cardinality than HTTP status codes.
Separately from emitting metrics, in order to build predictable HTTP clients, services have a predictable response behavior at the HTTP layer and map
Service Faults to HTTP status codes in the 5xx range
Client Faults to HTTP status codes in the 4xx range
Processing Errors to HTTP status codes in the 2xx range
Processing Errors are always serialized into and returned reliably in the application response, so (a) that the client application has a chance of observing them and (b) the application can in turn return them to downstream systems.
Processing errors from an upstream dependency should be (a) expected and (b) passed through back to the client of the service endpoint, either (a) unchanged or (b) translated. There should be no confusion in the code between an expected processing error and an unexpected client or server fault.
Any server or client faults from calling an upstream dependency should be wrapped into a new Server fault.
If a service cannot get a valid response from a critical dependency and fails the transaction it should directly count against the service’s availability.
The definition of 'critical dependency' is defined by the service owner and allows for degradation and fallback behaviors.